
初めてEKSのバージョンアップを行いました。
今回はv1.26からv1.29へのバージョンアップでした。
クラスターの構成としては、ワーカーノードが1台のシングルノード構成です。
インプレース方式で、先にクラスターをv1.29まで、そしてそのあと各アドオンをバージョンアップするという順序で行いました。各アドオンは、基本的にはArgoCDからバージョンアップを行っていました。ほとんどのアドオンはHELMで管理されているCHARTを使用しており、今回対象となるEFS CSI ドライバーもCHARTで管理しています。
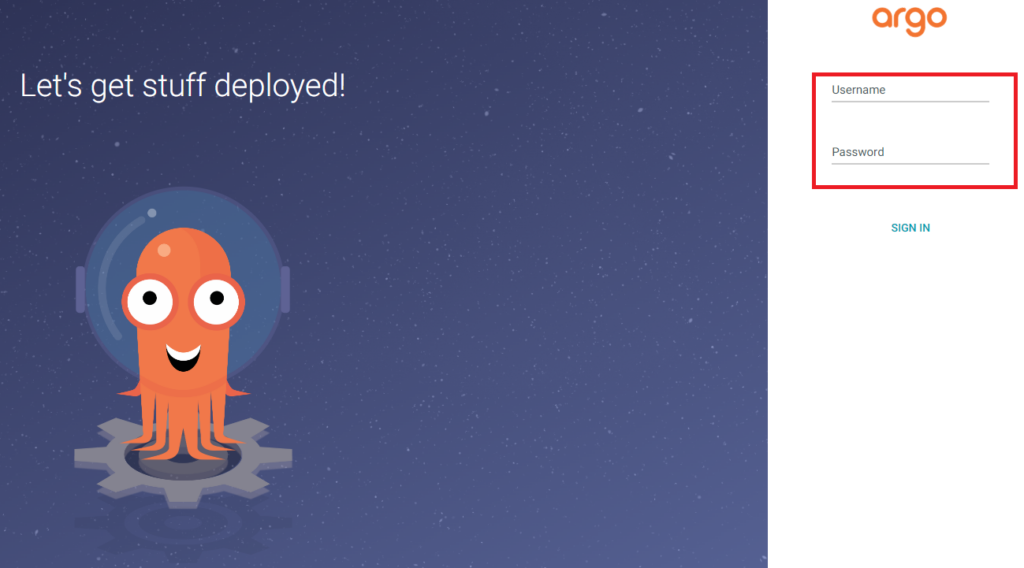
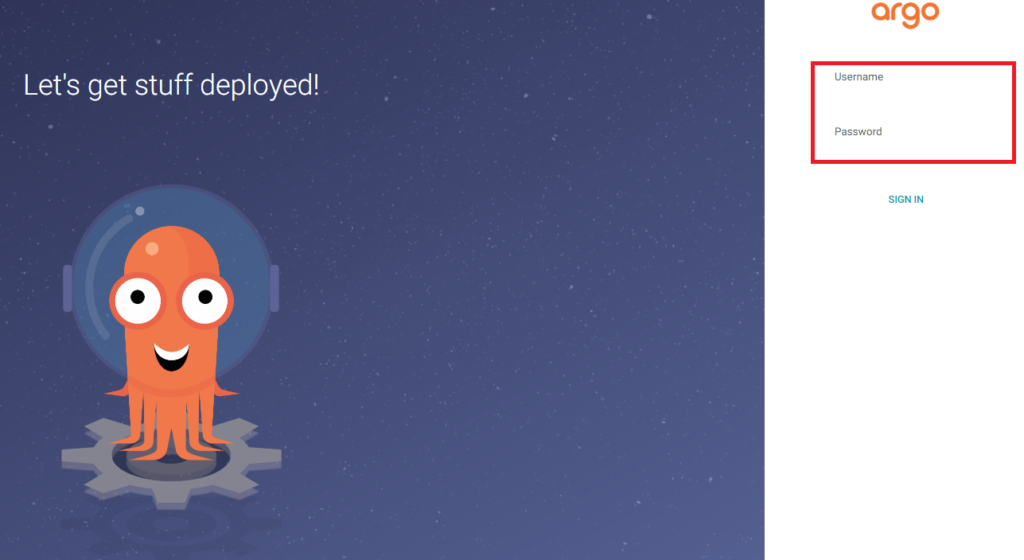
少し脱線しますが、ArgoCDをv2.7.3からv2.10.9にバージョンアップした結果、GUIのログイン画面でUsernameとPasswordの入力箇所にあった下線が消えました。
意図的なのかミスなのかわからないですが、UIとしてはかなり悪くなっている印象があります。線一つでこんなにUXが変わるのかとびっくりしました。
Before
After
閑話休題。
クラスターのバージョンアップが順調に進み、各アドオンのバージョンアップもサクサク進んでいたのですが、EFS CSI ドライバーだけがうまくいきませんでした。
新しく立ち上げたコントローラー2台がpending状態で、うまく起動していません。
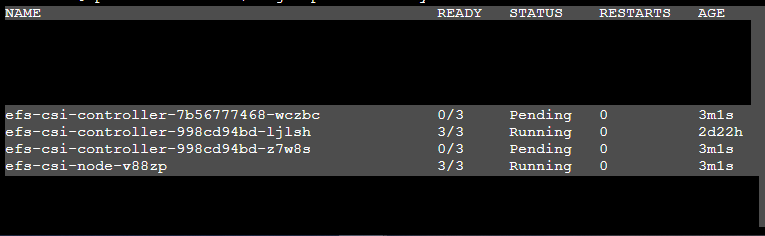
これらのpodを生み出しているefs-csi-controllerというdevelopmentをdescribeしてみました。
kubectl describe deployment -n kube-system efs-csi-controllerすると以下のような出力が得られました。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 4m25s (x45 over 24m) default-scheduler 0/1 nodes are available: 1 node(s) didn't have free ports for the requested pod ports. preemption: 0/1 nodes are available: 1 node(s) didn't have free ports for the requested pod ports.nodeのportが空いていないため、podを立てることが出来ないというエラーが出ています。
GPTに聞いたところ、こんな返答が返ってきました。

5つの手順が書かれていますが、まとめてしまうと「portが不足している」or「リソースが足りない」のどちらかが原因かのように思えます。
しかし、他のアドオンのバージョンアップは問題なく行えているし、リソースもワーカーノードのCPUもメモリも余裕を持ったスペックを使用しているので先ほど挙げた2点に問題はないように思え、ここで詰まってしまいました。
ただ、いくら調べてもバグ報告のようなものは見当たらないので、やはりクラスター側に問題があるのだろうと思い調査を進めていました。
ここで、出力されたエラーに立ち返ってみました。portの問題だと表示されているが、他のアドオンが更新できているからおそらくportには問題がない。実はシングルノードなのが問題で、
efs-csi-controllerはノードにつき1台しか立ち上がらないのではないか、と推測しました。
実際、シングルノードでは立ち上がらなかった、的なissueも発見しました。
issue上は解決済みとなっていますが、closeされた後でも同じような報告がいくつかあります。
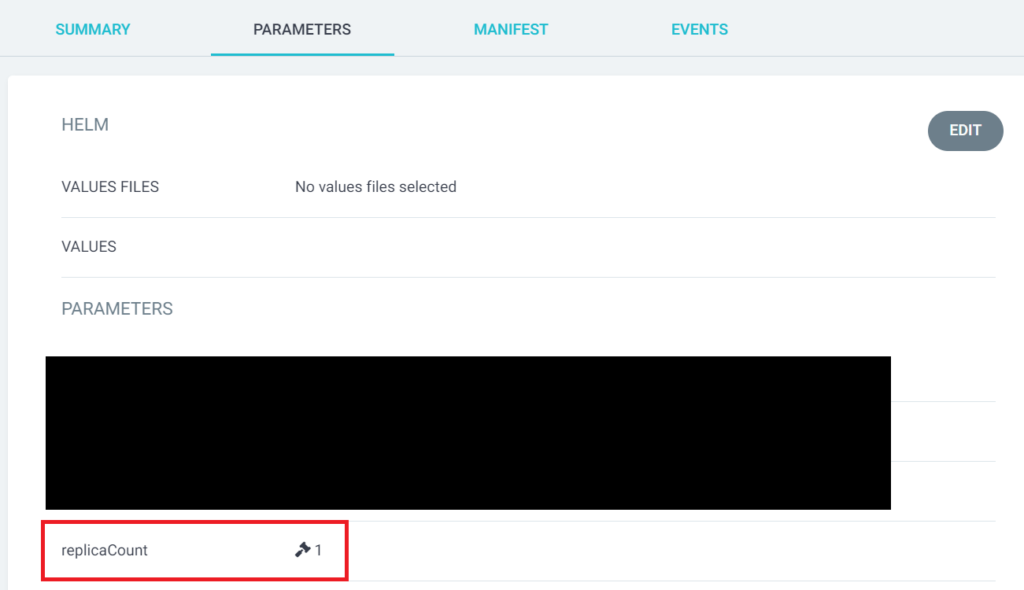
そこで、ワーカーノードを2台に増やし、efs-csi-controllerのレプリカ数を1にしてアップデートをしてみたら、上手くいきました。
efs-csi-controllerのレプリカ数を1にするには、PARAMETERSからreplicaCauntを1に変更します。
上手くいったので、やはり自分の予想が当たってた!と少し悦に入りました。
nodeAffinityでrequiredDuringSchedulingIgnoredDuringExecutionの設定がされているのかな?などと思いましたが、efs-csi-controllerのテンプレートを確認しても特にそのような設定は見当たりませんでした。

検索してみても各ノードにつき1podしか立ちあげられないというような情報は出てきませんでした。
やはりport関係なのか……?と思い、portに関する記述の箇所を見ると、containerPortが指定されていました!
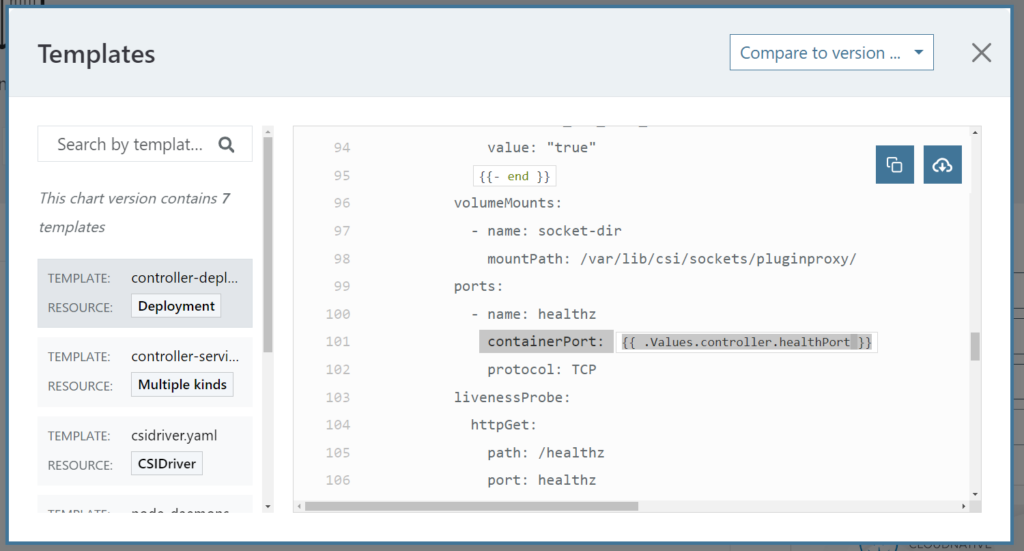
1つのnode上には同じcontainerPortを使用するpodは立ちあげられず、ローリングアップデート方式でバージョンアップしようとしていたのでpodがpending状態のままになってしまっていた、というのが全容でした。つまり、ローリングアップデートで更新したければ、レプリカ数よりも多い数のワーカーノードが必要だということになります。
contoroller.healthPortの値を変更するという手もありますが、他のところにも影響が出てしまいそうなのであまりお勧めしません。一時的にワーカーノードを追加する方が簡単でリスクが低いと思います。
結局元のエラー出力をありのままに受け取って調査していれば無駄な時間を短縮できたなあ……
と少しテンションが下がりました。
EKSは基本的にシングルノードや2台のノードで本番稼働することはあまりないと思うので発見されづらい詰まりポイントかなと思います。ただ、開発環境ではこのような構成はそこまで珍しくないと思います。この記事が参考になれば幸いです!

